· Programming · 9 min read
Why Program Generation Is the Monster Problem
After four months building a scaling engine that plateaued at 91%, we figured out why. Here's the token-first architecture every program-generation engine actually needs -- and why program generation is the real monster problem in fitness.

Ten years into Level Method. One year into custom MAPs. Four months into v1 of our scaling engine -- 91% of 10,000+ scaled movements passed, and that was the wall. Last week we realized why -- and the architecture we should have built a year ago.
It started with the MAP, not programming.
Level Method started with the MAP. Our first MAP had 15 categories -- our best effort to mirror what broad functional fitness demands. Every assessment on the MAP connects through levels considerations to individual elements inside a workout -- not just "whole level." If you have a Deadlift level, and there are deadlifts in the workout, we can calibrate that element. That connection is what lets a BLUE Level athlete and a YELLOW Level athlete do the same, equivalently individualized workout, each at their actual level, without either one getting a watered-down version of the other's session.
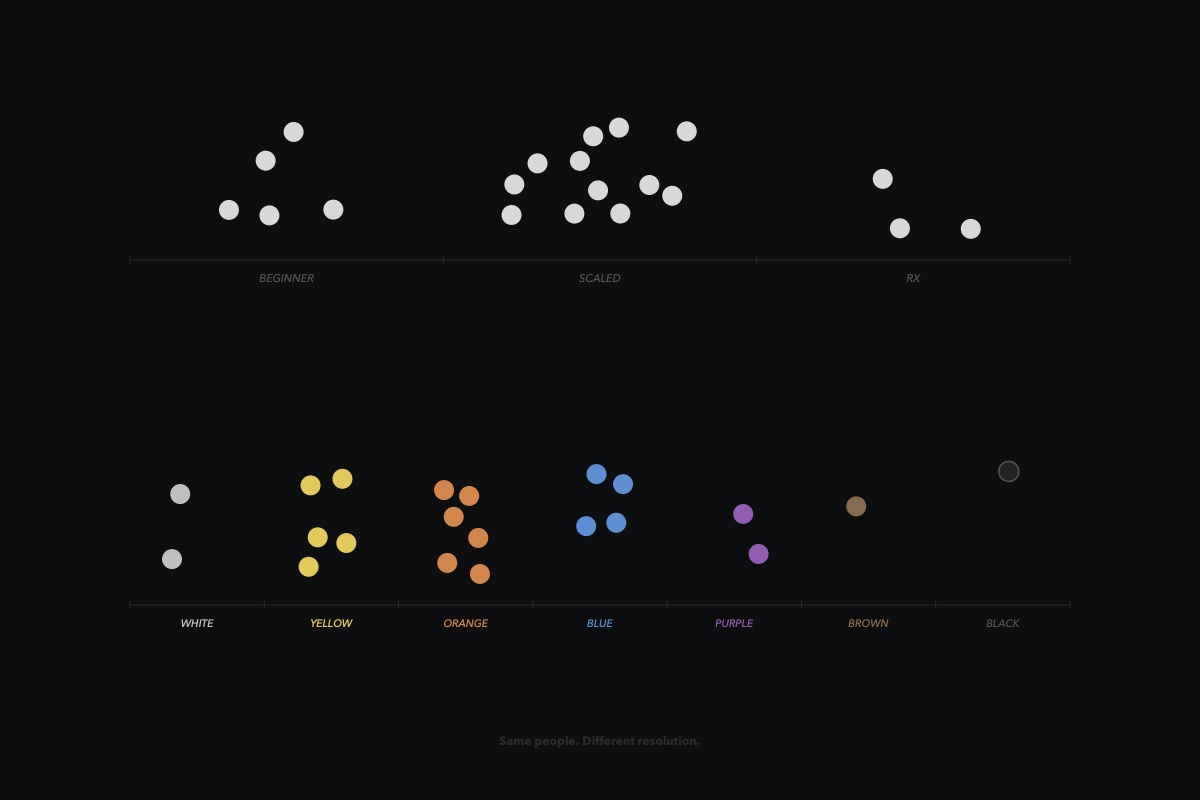
LIT programming came next, to serve the MAP. We didn't actually start out providing programming... because programming is and should be highly varied depending on the population. When we did introduce programming, we weren't even planning to do it leveled! LOL. Providing 7 levels seemed like a ridiculous amount of extra work. 7 levels for EVERY WORKOUT!? Yes. Seven levels. White Level through Black+. Levels are a shared language between programming, coach, and athlete so a human knows exactly where they are in fitness and where they need to go to improve.
(Shoutout to Chalk It Pro -- built by Nate and Jose to solve leveled-workout display, now doing full end-to-end gym management on top of the best displays in the business.)
But last year we opened the next door. Custom MAPs.
Different worlds weight different qualities. CrossFit-style fitness. HYROX prep. An individual on LM Individual with their own levels, injuries, history, and goals. A specialty gym with its own identity. Each needs its own world and programming calibrated to it.
A MAP is a set of assessments that reflect the world YOU care about. Then we add level considerations and the elements that connect them to real workouts -- so the MAP data is actionable day to day, in training, calibrating, scaling. Not train-to-the-test.
We built the tools to assemble any MAP -- the custom MAP builder, the in-gym display, beta categories. Any gym, individual, or track can now build theirs.
Which forces the next problem.
A MAP without programming is a list. Every world needs programming that actually serves it. You can't hand-write that at scale. One brain cannot author the right stimulus, at the right level, for every MAP and program, every day, forever.
Program generation is the inevitable next step. It's also a monster problem that nobody has solved. Scaling -- done right -- is a stimulus, appropriateness, specificity, progression, variance, and individualization problem, all at once. What the industry calls scaling is string substitution. That's the gap.
The industry's answer for twenty years started as just "Rx," with Scaled and Beginner layered on top later. Three big buckets for the full range of human beings. It's an airplane seat -- fits everyone ok, nobody really well.
And before any of that -- before Rx, before Scaled, before Beginner -- is actually writing a good program in the first place. Knowing the person. Knowing what they want. Knowing the goal. For gym classes that's impossible by definition. You're not programming for any single person. You're programming for an avatar, a hypothetical. The only way that hypothetical gets individualized is through the medium of a coach. And writing a good program is very hard by its nature.
Here's the best version of that argument: a great coach in the room fills the gap. Three buckets plus a skilled human flexing in real time covers most of what any athlete needs. The system doesn't have to be smart if the coach is. Same idea for program design -- except design happens virtually, through the written workout, so the coach-in-the-room safety net isn't there.
But coaches vary day to day. Experienced coaches are rare and expensive. New coaches need something to lean on. We wanted a system the best coaches would love AND the newer coaches could trust. Past that, everything downstream depends on how good that one human is that one day. That's the bottleneck we've been trying to move for a decade -- pretty much every LM detractor doesn't understand this.
The breakthrough last year. Fractal tokens.
Not LLM tokens. We mean structured programming units. Each one is a labeled object -- like a form the engine fills in, not a sentence it has to parse. Stimulus, movement pattern, structure, load -- every field tagged, every value typed.
That's the unlock. The engine can reason about the whole library at once because every piece is shaped the same way. Ask "show me every workout that taxes hinge-power endurance with a kettlebell" and it actually knows what that means -- instead of trying to parse 500 freeform descriptions.
We called this unit the Micro Block Token (MBT). A micro block carries stimulus, movement, load, reps, and structure. Workouts compose from micro blocks (they are micro blocks). Days compose from workouts. Programs compose from days. It's a fractal layer -- vertically trackable.
But the MBT isn't actually the atomic unit. Inside every micro block are movements, and movements carry attributes -- pattern, skill requirements, limiters, equipment, what makes one harder, different, more or less appropriate than another. If the engine can't reason about a movement, it can't reason about anything built on top of it.
So we had to deconstruct every variable worth having about a movement -- the ones that would let rule sets, weighting structures, and program design logic actually work. That's the movement database. Not a reference table. The atomic layer under everything else.
We built the first full fractal token ecosystem and v1 of the movement database last year. Ideas framed. Not fully locked in.
The scaling engine is the bridge.
Program generation is the destination. The scaling engine is step one -- and the proof. If the tokens can hold a workout's stimulus across all seven levels while flexing everything else, the architecture works and every layer above becomes possible. If they can't, nothing built on top works either. You don't generate programs from scratch before you can scale an existing workout cleanly. Scaling is how you earn the right to generate.
Then we made the sequencing mistake.
Fractal tokens are complicated, and we thought we could solve the scaling engine problem without them. So we focused on text parsing. Manipulate the strings -- if we have enough leveled workouts, and with AI, this should be no problem! It was doomed from the start. We should have started with tokens. Four months in, v1 works: 91% pass rate across 10,000+ scaled movements. WHITE 83%, YELLOW 90%, ORANGE 92%, BLUE 93%, PURPLE 95%, BLACK 97%. Good. It wouldn't go further. And it was badly overfit.
The plateau wasn't a quality problem. It was a representation problem. v1 manipulates raw text -- movement names, reps, loads. It can't preserve the core, the thing that actually matters: the stimulus. Energy system hit. Contraction type. Skill demand. Volume appropriateness. Lose the stimulus and you've generated a different workout, not a scaled one. You can't flex around something that doesn't actually exist and isn't modeled.
So we came back to MBTs realizing they had to be the foundation. And before MBTs could work, the movement database had to be completely, 100% solid.
The movement database got fully locked this week as the MBT foundation. ~600 movements to start, each described across 19 properties -- deep enough that the engine can reason about a movement, not just name it. Each property is a lever for substitution, scaling, or validation -- foundationally, program generation. A name plus three tags can't scale, can't substitute cleanly, can't flag bad reasoning. 19 can. That's the ingredient layer every engine above it depends on. More movements are coming. Eventually all of them.
That's the foundation. What gets built on top is v2 -- token-first, with each level authored natively (White Level isn't "Brown Level minus stuff"), generation is anchored against similar tokens already authored at the target level, and every generated token validated against its peer cluster so mismatches flag for human review. A learning loop v1 couldn't have. The system should get smarter every time a coach corrects a flag. That's the path we see forward.
The pattern isn't new. It's new to fitness.
The cooking world solved this architectural problem over a century ago. Not in the recipes themselves -- in the describer substrate underneath them. Ingredient taxonomies with properties and aliases. Substitution graphs that know when swaps preserve the dish and when they break it. Technique classifications. Equipment as first-class schema. Skill-tiered versions of the same dish, each authored at its level.
Every v2 primitive has a direct parallel. Movement DB is ingredient taxonomy. Ladders are substitution graphs. An MBT is a structured recipe object. Workouts are meals. Programs are meal plans. Seven levels are ability tiers.
We didn't invent any of this. We're just applying it to fitness.
What it unlocks.
Program generation that serves every MAP, intent, goal. The gym floor. The individual on LMI. The HYROX track. Any future world where calibrated programming is the job. Same stimulus, delivered to every human based on where they actually are. Not dumbed down. Calibrated.
To build the v1 scaling engine we tested on 529 workouts. Now with v2 it's those 529 workouts × 7 levels = ~3,700 tokens as our cold-start corpus. Every additional workout layered in compounds. Every correction teaches the system.
Why we're not worried about AI-generated workouts.
Most of what's coming in the fitness space with AI is LLM-generated workouts with no representation underneath. A chatbot in a coach skin. It generates something that looks like a well-thought-out workout -- it will give ok outputs. But it can't reason about what the workout does. No objective measurement. No stimulus model. No level-native tokens. No anchored generation. No validation loop.
This is the same pattern that just gave us a 91% ceiling on v1. Text-out without representation-under works until it doesn't. You don't fix it with more compute or a better prompt. You fix it by building the substrate underneath. AI on top of a real representation is how v2 generates. AI AS the representation is a dead end. The difference is whether the system knows what a workout DOES, or just what a workout LOOKS LIKE.
We spent a year working out the architecture that makes real reasoning possible. Now we just have to build it.
There's a self-serve programming tier built on this engine, coming soon. Get on the waitlist to be first in when it launches.